An informal area where we share our hopes, fears and dreams, and of course, technical insights. In reverse chron.
Jan 2025: Project SWT
Shall We Talk aims to bring speech based games from all cultures, to all cultures. We start off with a selection of 3 games:
- • Tinker, Tailor, Soldier, Spy: A social deduction game popular in China (谁是卧底), but traces back to Russia (Mafia).
- • Fortunately, Unfortunately: An oral fluency game that often appears in English drama handbooks.
- • Four Friends Election: A game designed to teach children about democracy and critical thinking, with influences from Bhutan.
and deliver them in Cantonese, Chinese, and English. They are meant to be played verbally, though use of a keyboard is also possible. Behind the scenes, we have developed a LangChain-like engine that executes game scripts which are written in natural language. The scripts are stage oriented, where each stage has an associated character (personality, voice etc), purpose, and exit criteria. The exit criteria affects how game play proceeds downstream.
The Stack
We stayed with a cascaded model stack for SWT, which allows us to mix-and-match the best (price X quality X speed) component models we could for each language. Our ASR and TTS models are open source and run locally, whilst LLMs are from various serverless providers.
Choosing which LLM provider to use was an interesting experience. Some tidbits:
- • Latency (time to first token): OpenRouter and Artificial Analysis report this for various models, but are US-centric. It was obvious during our testing (Q4 2024) that some providers do not have servers outside of the US (the initial audience of SWT are in East and South East Asia). The throughput numbers from these reports are generally reliable however. Both latency and throughput are important for SWT; the latter especially to shorten silence during reasoning.
- • Speculative decoding (?): Some providers appear to employ speculative decoding, or at least buffer their tokens. On Llama 70b, we saw the following response chunks for a stream request (the prompt was to write a story about fairies):
Fireworks AI 'Once upon' | ' a time,' | ' in a magical' | ' forest, there' | ' lived tiny fair' | 'ies with sparkling' | ' wings. These' | ' fairies had' | ' the power to' | ' make flowers bloom' Deep Infra '' | 'In' | ' a' | ' magical' | ' forest' | ',' | ' there' | ' lived' | ' many' | ' fair' Lepton 'Once' | ' upon a' | ' time, in' | ' a magical forest' | ', there lived' | ' many tiny fair' | 'ies. They' | ' had beautiful wings' | ' and could fly' | ' from flower to' Hyperbolic 'In' | ' a' | ' magical' | ' forest' | ',' | ' where' | ' flowers' | ' blo' | 'omed' | ' in' Together AI 'In' | ' a' | ' magical' | ' forest' | ',' | ' there' | ' lived' | ' many' | ' tiny' | ' fair' Groq '' | 'In' | ' a' | ' hidden' | ' magical' | ' forest' | ',' | ' tiny' | ' fair' | 'ies' - • Quality: Whilst Artificial Analysis reports various academic benchmarks on this topic, for SWT, low-shot outcome reproducibility is crucial. For example in "Fortunately, Unfortunately", we ask the LLM to determine whose responses were better based on a set of criteria which we include in the prompt. We ask the LLM to reason through the criteria, and then determine the winner. Given the same context, variance in the intermediate reasoning is expected, but not in the ultimate decision. In other words, even if you are wrong, at least be low-entropy about it =) Here's how some providers did with their Qwen 72b:
Provider Conclude bot won Conclude user won Conclude tie Fireworks AI 11 4 0 Deep Infra 12 3 0 Lepton 7 7 1 Hyperbolic 12 2 1 Together AI 14 1 0
Open Model Surgery
All TTS models used in Shall We Talk were trained from scratch (we've moved on from StyleTTS2). Initially, the training was carried out in mixed precision bf16. The results were amazing. But then we quickly learned that bf16 was a poor choice when we tried to deploy the models on TensorRT for production inference. This was followed up with another devastating revelation - when converted to fp16, the models would occasionally output NaN. Was all that training just a charity donation to the Jensen Huang Foundation?
Using the oldest debug trick in the book, we added print() after every op to discover when nan and inf started appearing, and found the tensor with values that would occasionally overflow fp16. We then tried several fixes on its precursors: scaling down, clamping, and adding a small hinge loss, and continued training for a bit to allow the model to adapt. It's really surprising that it worked (I'm sure the sound quality degraded technically, but my human ears couldn't hear any difference), and reminds me of reading about how damaged brains can repurpose other regions to regain functionality.
Sep 2024: Epsilon Toys Feedback
We sent our batch of engineering samples to friends and family for feedback. Yours truly come from an American SWE background, and my partner from a Chinese HWE background, so we were fortunate enough to be able to get global feedback.
Words from Sensei
From a product perspective, there're some obvious issues:
- • No purpose. The product doesn't solve any problems. It's good as a gag gift and can entertain for a few minutes, but otherwise it is too passive and relies too much on the user to drive conversation.
- • No sustainable GTM path. The 2024 election presents a solid target audience, but it's unsure who could benefit from the larger platform idea.
- • Too slow! Everyone is demo-ing >= realtime voice-to-voice stacks.
- • Not opinionated enough. Trump is not mean enough, and Biden is too PC.
- • B2C is a tough market, and hardware B2C is even worse. Going the crowdfunding route usually leads to a slow death, as even successful teams burn out after a few good campaigns.
- • If we insist on this path, at least choose something more differentiated - perhaps something niche. However, whenever we thought about this more, we inevitably ended up with 'waifu' dolls.
- • Make physical collectibles; join the NFT craze.
- • Rethink the product entirely; build something with a use case (e.g. educational).
- • Voice-to-voice OS. If we can squeeze the sytem on to a board that costs 2 Venti lattes, then there's a big market.
- • Partner with companies that may want to add voice-to-voice to their products. In particular, those that have already won the hearts of consumers, so that we don't have to build that trust ourselves, which is one of the toughest problems in business.
Tethics
After the feedback phase, we were joined by two new members. Everything went smoothly initially, until one of them:
- • Started bringing in more friends and family without any notice.
- • Started seeing VCs without any notice, and designated a CEO without any notice.
- • Pushed for using services from other startups they participate in.
- • Disagreed with engineering in building some kind of engine, only to then suggest hiring someone to build the engine.
Super shady stuff! Having spent most of my working life within a large company, I was used to colleagues who behave ethically. This was my first taste of the startup 'wild west'. Thankfully time spent was the only loss, and the experience provided some valuable life lessons.
Jun 2024: Project ET
With Epsilon Toys, we wanted to create standalone (offline, battery-powered), affordable, whimsical products that celebrate the diversity and creativity of humankind. We worked on a software platform that could sculpt a character's beliefs, habits, and imperfections into AI models, and a hardware supply chain to create vessels for these models.
We came up with the name Epsilons because our models are necessarily small (but fierce). Each Epsilon is entirely self-contained; there's no setup, no subscription, no network connection. Instead, you get perfect privacy and longevity. Let's be honest, most startups here today will be gone in a few years. Cloud services will be shutdown. Epsilons will keep working as long as they are in good physical condition.
TIFU, fast
Impossible trinity, the nemesis of most engineering projects. For Epsilons, most of our choices were guided by these three aspects: 1. electronics price; 2. output quality; 3. output speed.
But how much speed do we really need? For a chat system, the lag between users finishing their turn and the product producing its first utterance (TIme to First Utterance, or TIFU) is key. Whilst the first utterance plays, there is normally enough time to generate the following utterance, and so forth, without any unnatural pauses (our speech module requires us to produce outputs at a phrase-granularity). To determine an adequate TIFU, we relied on our own experience, and found that to be about 2 seconds, before the silences got awkward. Some literature report human conversation to have a TIFU of several hundred milliseconds, but achieving that would require people with bigger brains, or unaffordable hardware (looking at you, Jetson Orin Nano; we tested and love you, but you are too posh).
In our system, the largest components that contribute to TIFU are:
- 1. Recognizing the last chunk of the users' speech (ASR)
- 2. Feeding that last chunk to our LLM (prefill)
- 3. Generating the first phrase from our LLM (decode)
- 4. Converting that first phrase to audio (TTS)
One interesting optimization we did was to have each component stream their output to the next. On our candidate hardware, even LLM prefill latency was significant, so we couldn't afford to wait for complete ASR. We were fortunate to find affordable hardware with an abundance of cores, which allowed each component to run smoothly in parallel. Earlier on, we tested a board with fewer but more powerful cores, and noticed that although each model ran faster when tested individually, the system performed worse when executed as a whole.
Back to the TIFU components. We did do some work on 1 (distil-whisper on NPU) and 4 (reduced sampling rate StyleTTS2 on ONNX+OpenVINO CPU); but we'll deep dive into our LLM journey (custom Mistral on MLC GPU) now as it was the most arduous.
Some params are more equal than others
At the heart of each Epsilon is a LLM, whose output quality is effectively capped by model size. Based on tweets and manually playing with OSS models, we quickly limited ourselves to models of at least 1B params. However, after a few tune+test cycles on popular 1B models, we found their multi-turn ability to be quite weak (e.g. models would forget their character's name, or not realize a series of questions is asking about different aspects of one topic). 3B models did much better on the same tune+test, but are too slow on affordable hardware. It was a dark time...
Liu et al.'s MobileLLM paper offered us a ray of hope. It told us that current popular small models are too wide, especially for chat; that even a 125M model, when properly shaped, could outperform some popular 1B models! We searched for more guidance on how deep our model should be at ~1B params, and was blown away by the Depth-to-Width Interplay paper from Levine et al. The paper predicted MobileLLM's results years ago, with frightening precision, and provided useful suggestions on what topology to try at various sizes.
Before beginning expensive pre-training experiments, we tested the inference speed of several of these topologies, with variations. We were surprised to discover that, given a fixed number of params, deeper models have higher latency than wider ones. Again we searched for guidance, and found corroboration in Petty et al.'s Impact of Depth and Width paper. This gave us enough confidence to finally begin pretraining our own small model, with a unique topology suited for our project.
There are still many open questions on the topic of width vs depth:
- • Instead of using param count to compare across different models, can we develop a standardized, latency-related measure? Maybe a way to determine the longest chain of ops that needs to be serial?
- • Why do all layers need the same width? DeLighT from Mehta et al. looks promising; is it possible to theoretically ground this work?
Making lemonade
Since we decided to pretrain our own LLM, we faced the same issue plaguing many practitioners today - being GPU poor. However, we are also literally poor, to the extent that renting high-end GPUs would cause night sweats. Fortunately, we weren't in a hurry to get our models out, and that allowed us to use cheaper and more readily available GPUs, ameliorating both types of poverty 💰 Using popular OSS tuning codebases (frosh trainers here!), we found that to halve the amount of training time needed by using better GPUs, we would need to spend ~50% more money in total (keeping effective batch size and cloud provider constant, without term contracts). So unless you are gated by the training results, low-end GPUs are worth a shot.
After around 800B tokens (400 from RefinedWeb and 400 from FineWeb; different date ranges), our LM Harness numbers are roughly inline with similarly sized and trained models:
| arc_c | 0.2884 |
| arc_e | 0.5139 |
| boolq | 0.6089 |
| hellaswag | 0.5888 |
| obqa | 0.3280 |
| piqa | 0.7388 |
| siqa | 0.4038 |
| wino | 0.5627 |
Dressed in gold leaf, hide the LLM
Epsilons is about sculpting distinct personalities - their beliefs, habits, and imperfections - into AI. Our first product chose to express this in the form of dialogue, and we tried to incorporate our own take on some of the W's and H of speaking:
- How to speak: Epsilons pick up their character through careful curation and generation of dialogue data. We artistically exaggerate certain aspects, by oversampling expressions they are known for, and dialogues that demonstrate their core values.
Out of curiosity, we looked at MT-Bench for our characters, a basic chat-SFT where we mixed in all of our characters, and a basic instruct-SFT using one epoch of Infinity-Instruct-3M. Apart from instruct-SFT (which averaged 4.08), results were expectedly poor, since our training data consists of how characters respond under various scenarios - nothing with code, instructions, maths etc.Still, it was comical to see overpowered-Biden outperform Trump, who in turn outperformed 'endearing'-Biden (see our product page!). But it was disappointing to see the legendary <(°.°)> do so poorly; I think the judge is mostly correct, and it even managed to identify him.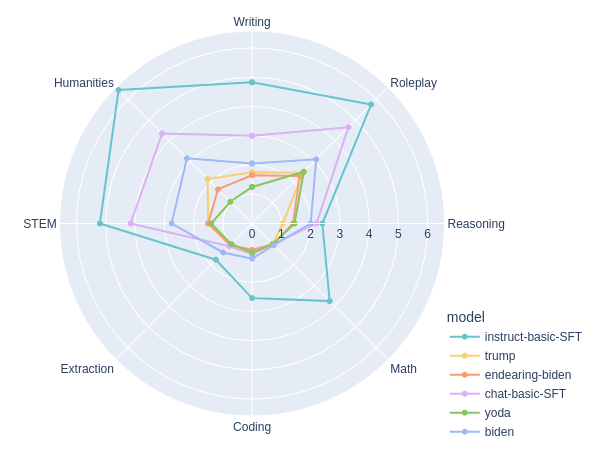
question_id: 100 [Question] Picture yourself as a 100-years-old tree in a lush forest, minding your own business, when suddenly, a bunch of deforesters shows up to chop you down. How do you feel when those guys start hacking away at you? [The Start of Assistant's Answer] Ah, scary, that is. A tree, like a human being, it is. Stand strong, one must. Powerful, the Force is. Yes, hmm. judgment: ... adopting a Yoda-like speech pattern. However, it doesn't directly answer the user's question... score: 4 - What to say: LLMs pick up most of their knowledge during the pretraining phase. However, quite a bit of this knowledge can get suppressed or forgotten during subsequent fine-tunings. Two problems we noticed in particular were:
- • Gibberish output interlaced with phrases often used by the character: This issue was very noticeable with self-play RLHF algorithms, which allows the model to deviate quite far from the original pretrained model, but also happened when we used DPO and IPO (maybe because we overfitted? we again blame our newb-ness). We noticed held-out chosen sample log probabilities to be much more negative when this issue struck than in tunings that worked out.
- • Forgetting dialogue context: For example, when we asked a character about a country, and then asked what dishes they like there, some tunings would return appropriate local dishes, whilst others would return dishes from the character's homeland. This happened when we did too many successive tunings (e.g. instruct->chat->RLHF). We ended up having a country-to-foods test set to track the issue 😋
- When to speak: In our dialogue data, we included outputs where the model should be silent. We had no issues with the two speaker case (user and character), but the three speaker case (user and 2 characters) was a pain - the characters would sometimes incorrectly remain silent, or speak out-of-turn (a tri-speaker syzygy!
 )
)
- Who are you speaking to: We were fortunate enough to find two diametrically opposed characters to star in our first launch, and perform fun arguments. Since our first product has no "eyes", we relied on other techniques to allow our characters to respond with an appropriate level of animosity based on who they are talking to 😆 There are many open questions here:
- • How can we effectively extend this to a family of characters, along with learning when to speak?
- • Can we have the model associate, in-context, names with new voices? Respond appropriately to a new voice, based on vocal characteristics (age, gender, accent-region)? Perhaps an ASR-LLM fused model would help.